

宮迫博之さんと宮島保之さんの名前の似てる度は0.5です

それはさておき、今回は文字列同士が似ているかを比較するプログラムを作成しました
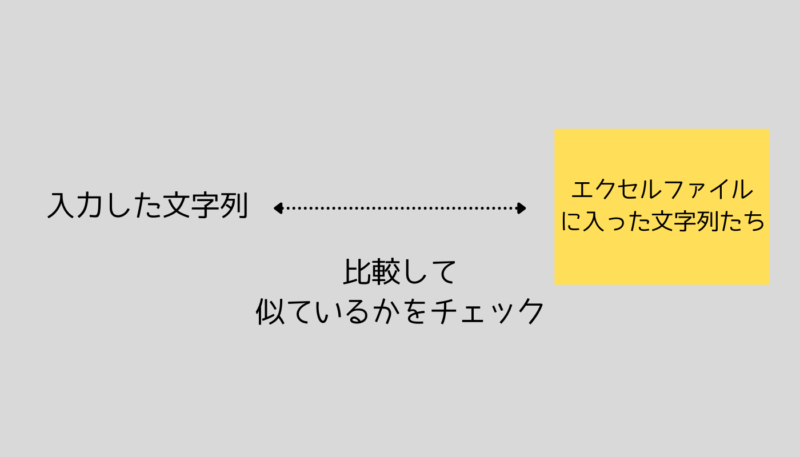
だいたいこんな感じの仕組みです
早速ですが、下にコードを載せますね
※2021/08/23に内容更新。漢字の類似度を計算する方法をゲシュタルトパターンマッチングから、
ジャロ・ウィンクラー距離方式に変えた。
コッチのほうがしっくり来たので。
# https://blog.mudatobunka.org/entry/2016/05/08/154934 類似度チェック 参考
# 文字列に対し、どのような違いを見つけているかというのの検証しているURL https://qiita.com/shoku-pan/items/8185dba860bb7b7aed67
import collections
import sys
# 人名の入ったファイルのパスを指定したい。実行ファイルと同一フォルダ内の特定の名前を指定
def get_dir_path(relative_path):
import sys,os
try:
base_path = os.path.dirname(sys.argv[0])
print(base_path)
except Exception:
base_path = os.path.dirname(__file__)
print(base_path)
return os.path.join(base_path)
def flatten(l):
#中身がリストのリストになってしまっているのを改善するための関数
for el in l:
if isinstance(el, collections.abc.Iterable) and not isinstance(el, (str, bytes)):
yield from flatten(el)
else:
yield el
def jinmeimei_hikaku():
# 必要なライブラリのインポート
# 計算方法をジャロ・ウィンクラー距離にした理由は、文字の場所の入れ替えに対し、
# しっかりと検知をしてくれていたため
import Levenshtein
import pandas as pd
df = pd.read_excel(jinmei_list,sheet_name=0,usecols=[0])
test = df.values.tolist()
namaelist = list(flatten(test))
# list の中に人の名前が全部入っている
hikaku = input("""
人名を入力>> """)
# エクセルファイルに入っている、比較したい名前の列部分をリスト化
d = {}
for jinmei in namaelist:
s = Levenshtein.jaro_winkler(hikaku, jinmei)
d[jinmei] = str(round(s,3)*100)+"%"
# 類似度が高いものの上位5番目まで表示
result = sorted(d.items(), key=lambda x: x[1], reverse=True)[:10]
return result
def jinmeimei_hikaku_yomigana():
# 必要なライブラリのインポート
import difflib
import unicodedata
import pandas as pd
import jaconv
df = pd.read_excel(jinmei_list,sheet_name=0,usecols=[1])
test = df.values.tolist()
namaelist = list(flatten(test))
# list の中に人の名前が全部入っている
hikaku = input("""
人名【よみがな・ひらがな】を入力>> """)
# エクセルファイルに入っている、比較したい名前の列部分をリスト化
# namelistに入れておいたお名前と、入力した名前を比較して辞書に追加していく
d = {}
for jinmei in namaelist:
jinmei_katakana = unicodedata.normalize("NFKC",jinmei)
jinmei_hiragana = jaconv.kata2hira(jinmei_katakana)
hikaku_hiragana = unicodedata.normalize("NFKC",hikaku)
s = difflib.SequenceMatcher(None, hikaku_hiragana, jinmei_hiragana).ratio()
d[jinmei_hiragana] = str(round(s,3)*100)+"%"
# 類似度が高いものの上位5番目まで表示
result_yomigana = sorted(d.items(), key=lambda x: x[1], reverse=True)[:10]
return result_yomigana
# ここの "\人名リスト.xlsx" は適切に変えてくださいね
jinmei_list = str(get_dir_path(sys.argv[0])) + "\人名リスト.xlsx"
print("""使う予定の正式な名前とよみがなを入力することにより、
同一フォルダに置いてあるエクセルリスト内の名前とよみがなを比較します。
1に近いほど似通っており、0に近いほど似通っておりません。
上位10名まで表示しています
""")
endless = True
while endless == True:
print(jinmeimei_hikaku())
print(jinmeimei_hikaku_yomigana())
input("""Enterを押すと、別の名前のチェックが出来ます
終了する際は、ウィンドウを直接閉じてください""")
このコードを書いたファイルと同じフォルダに、

こんな感じのエクセルファイルを用意してあげてください
※https://hogehoge.tk/personal/ というサービスで作成した実在しない人のリストでよければ、以下のリンクからダウンロードできます:)
以下、どういう風に活かしたのか、ということを書きます。また後ほどね。


コメント